简论图像匹配检索系统
图像匹配检索系统主要分为服务端和客户端两部分,客户端主要作用是向服务端提供图像,服务端的主要作用是向客户端提供图像匹配检索服务。服务端收到图像后会计算出图像的特征,然后查找出与所提供图像特征最接近的特征(可以是一个或多个)。此外,服务器还应提供特征索引功能且具备动态从特征库中增删特征的能力。以下从图像特征描述、特征索引和脱机训练三个方面简单介绍一下图像匹配检索系统,并对图像匹配检索系统的未来趋势进行展望。
图像特征描述
图像匹配检索引擎通过某种特征描述算法提取图像特征,一幅图像的特征可以是一个向量,也可以是一个二进制码,还可以是一组向量。传统的特征提取方案有多种:
- 局部特征提取法,利用SIFT、SURF、ORB等算法提取图像的稀疏局部特征,这样的特征表现为一组向量或一组二进制码;
- 全局特征提取法,如PHOG、GIST等,这样的特征表现为一个向量;
- Bag of features法,利用SIFT等局部特征提取方法提取特征,对特征进行聚类学习得到特征词典,然后再利用特征词典对一幅图像的局部特征进行编码,编码后的特征表现为一个稀疏向量;
- 深度卷积神经网络(CNN)提取特征,将深度卷积网络的最后一个全连接(Full connection)层输出作为特征向量,其中深度卷积网络是通过对大量有标记图像样本的学习得到;
现代的专用图像匹配检索系统主要通过机器学习(Machine Learning)的方式提取特征,所谓专用图像搜索系统是指专门针对某类物品进行设计的图像搜索系统,此类图像匹配检索系统所要处理的图像往往具有一定程度的相似性,但又存在细微差异,如行人再识别(Person Re-Indentification)系统即属此类。此类图像匹配检索系统的表现往往优于基于传统方法的检索系统。
有监督度量学习(Distance Metric Learning)从样本特征之间的距离或相似性关系中学习出对于样本的一种表示,这种特征表示对于相似的图像表现出距离相近,对于不相似的图像表现出距离相远,距离可以是欧式距离、马式距离及汉明距离等等。常用的度量学习方法分为线性模型和非线性模型,比较著名的有局部线性嵌入(LLE)法。而当前主流是采用基于深度卷积神经网络进行端到端(end-to-end)的度量学习训练,从而得到图像的特征表示,如Siamese网络。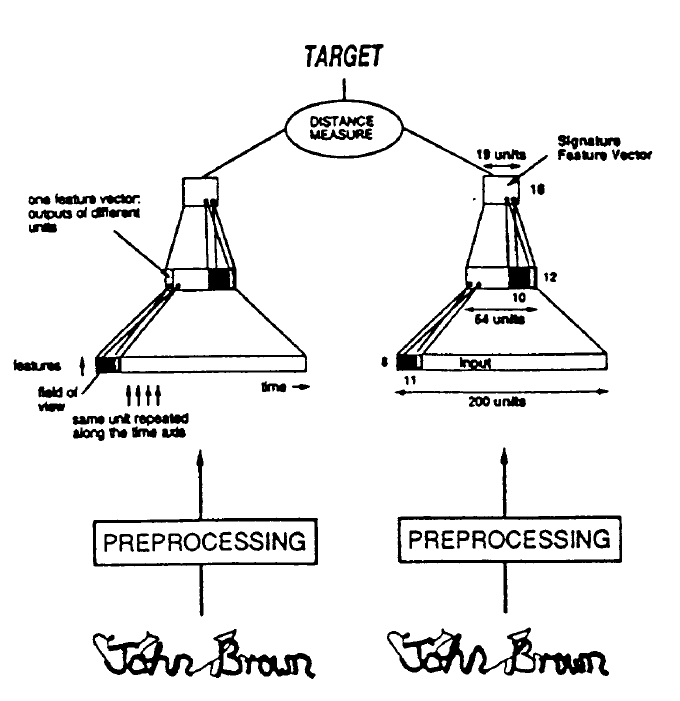
特征检索
根据图像特征类型、实际需求等方面的不同,图像特征检索可分为线性检索和索引检索,当前索引检索是主流,主要是因为其具有O(logn)的检索复杂度,大大降低了检索特征所需的时间。索引的方法主要有kd-tree随机森林索引方法、局部感知哈希(LSH)法等等。此外,对于大规模特征检索,一般的索引方法都可执行并行查找,以提高效率。
脱机训练
一般检索系统为了提升检索性能指标,系统多会采用脱机(offline)训练与在线(online)索引相结合的方案,即通过脱机对大量的图像进行学习,学习出一种描述图像的特征描述方案,此后在索引中对特征进行增删查操作时,只需采用这种图像描述方案来提取图像特征。
图像匹配检索未来趋势
给图像生成自然语言描述是图像信息分类的一个新的、重要的方向。为图像生成自然语言描述,然后通过自然语言这一高层语义将相关图像联系起来,而不是像之前那样通过图像特征来联系相关图像,势必会让图像匹配检索系统的智能程度和用户体验得到很大的提升,这是今后图像匹配检索系统发展的新趋势。
个人鄙见,仅供参考。
 本作品采用知识共享署名 3.0 中国大陆许可协议进行许可。
本作品采用知识共享署名 3.0 中国大陆许可协议进行许可。